- Follow us on mastodon @clld@social.mpdl.mpg.de
CLLD – Cross-Linguistic Linked Data
CLLD News
With clld 7.1 out of the door
![]() it’s time for an update on CLLD-related activities.
it’s time for an update on CLLD-related activities.
Some of CLLD’s “flagship” databases have seen some activity recently:
Glottolog
Glottolog is at release 4.2.1 meanwhile, and finally on a roughly biannual release schedule. This is particularly important, because frequent releases will allow faster addition of new data (e.g. to flesh out the dialect inventory) and correction of errors, thus make collaboration a lot less frustrating.
While frequent releases also mean that the amount of changes per update will be somewhat smaller than with less frequent releases, it may also mean that it is more often necessary to inspect changes between releases. With Glottolog releases at least twice a year, many research projects, papers or datasets will have to cope with a version upgrade of Glottolog within their “lifetime”. And while it is always an option to stick with an older release - these are long-term archived and available thanks to Zenodo after all - upgrading to the latest Glottolog version may help making research more relevant.
Thus, being able to inspect the changes between Glottolog releases easily has become more important. Now, for the sake of the editors’ sanity alone, we curate the Glottolog data in a version controlled repository on GitHub. So going back in time is always possible. And it’s even possible to inspect changes between Glottolog releases “through the web” - e.g. here is a link to the changes from release 4.1 to 4.2.1. But “Files changed ∞” doesn’t sound easily penetrable.
But starting with Glottolog 4.0, each release of Glottolog is supplemented with a
release of Glottolog’s core language data as CLDF dataset.
These releases contain a lot
less files and have a far simpler data structure, so inspecting changes becomes easier.
E.g. when inspecting the changes from 4.1 to 4.2.1 again, we see (when expanding the diff for cldf/languages.csv) that for example
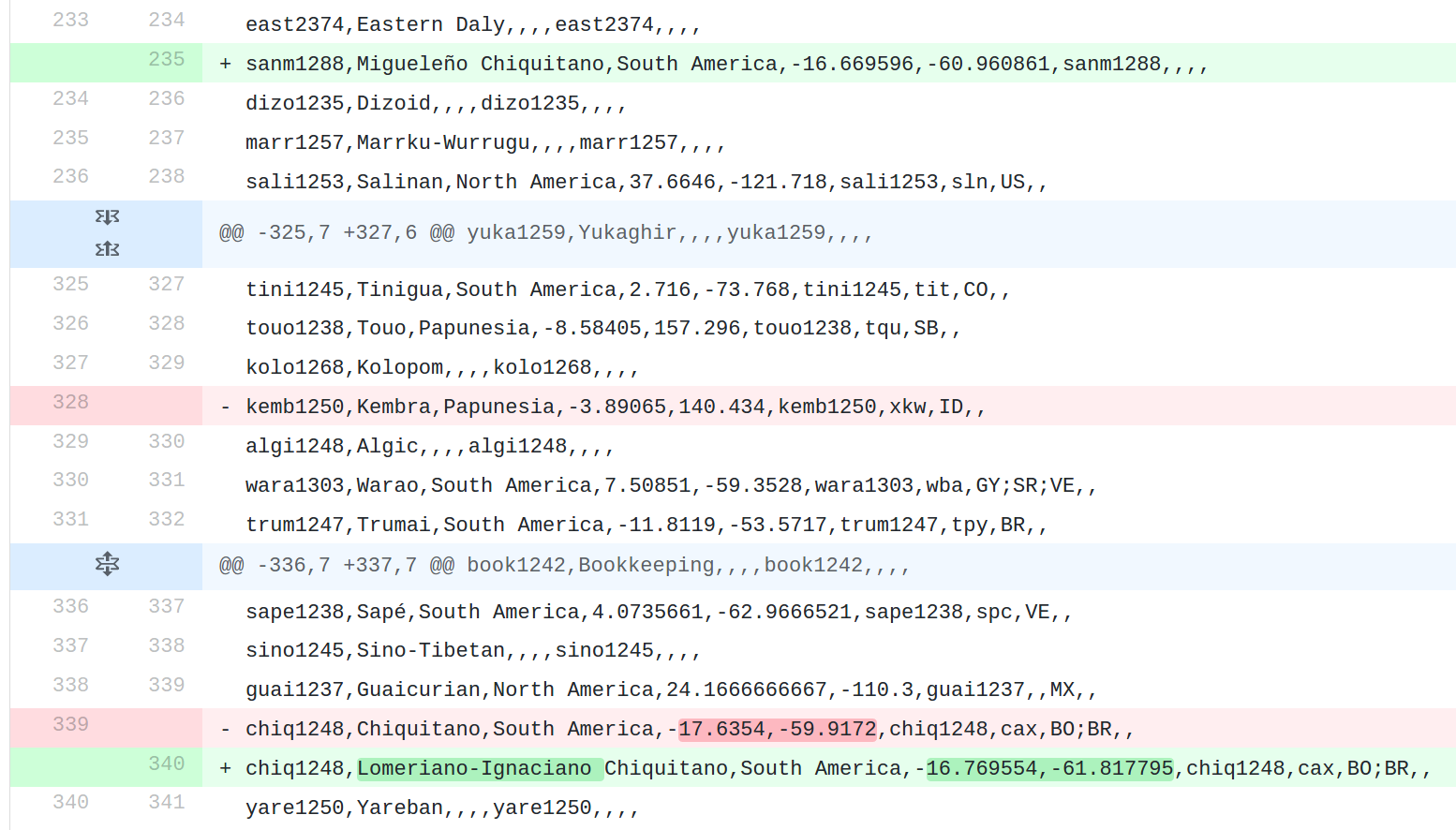
Thanks to the design of CLDF datasets, they are easy to inspect using simple tools, and a “recipe” in the Glottolog cookbook shows how to extract sets of changes between Glottolog releases which are amenable to human inspection.
WALS Online
The oldest CLLD database - WALS Online - has seen some activity, too, and again due to CLDF and the way it simplifies data curation.
When conceived, in 2008, WALS Online - the web application - was supposed to be the authoritative source of WALS data, i.e. any data access should go through the application. With the release of the 2011 edition, with more and updated data, this became more complicated. While the underlying database was powerful enough to deal with versioned data within the database, making these changes transparent and accessible for web site visitors was difficult. The 2013 edition didn’t exacerbate the problem, but there was still no satisfying solution.
With CLDF, we finally had a tool to separate data curation from data presentation. Thus, we built CLDF datasets for all editions of WALS Online and released them on Zenodo. Changes between these editions can be inspected as described above for Glottolog, or as shown on the WALS web site.
We also went one step further: The WALS CLDF repository on GitHub is now the place where WALS data is curated. I.e. errata can be posted using issues and the WALS Online web application is “merely” a place to window-shop the current edition. Actual access to and re-use of the data should go through the released CLDF datasets from Zenodo.
Since the CLDF format is well specified, we hope that more people than before will be able to re-use the data - possibly even sharing tools and recipes. In fact, we hope that the accessibility of CLDF will make up for the loss of the myriad of download formats we had for WALS before. As an example, we put together a description of how to create the “WALS feature matrix” from the CLDF data. If this description looks a bit messy, that’s partly because it describes “un-tidy-ing” data - which we don’t want to encourage :)
clld 7.0 with better support for CLDF
Finally, the clld toolkit - which powers all CLLD web applications - also received updates embracing CLDF as the new standard
for data curation.
This should not be very surprising, considering the history of CLDF (and the CLLD project). In 2014 we described clld as an attempt at “standardizing the Microsoft way” - i.e. data access can be standardized across datasets
when this access is mediated through the same software stack (just like Word documents were supposed to work everywhere - provided you open them with the Word program). But it was clear
from the beginning, that this is not really sustainable (not even when you are Microsoft) - in particular since it required
people to run clld apps to share their data in a standard way.
But clld helped us understand our data better and thus led to the specification of
CLDF - which can be seen as a specification of a serialization of the data model of clld applications.
So with CLDF available, we could turn our data curation and publication workflows around:
The primary data sources are now (versioned and published) CLDF datasets, while clld
apps - as described for WALS above - are relegated to marketing tools. This allowed us
to simplify the clld toolkit, e.g. removing support for in-database versioning.
But on the other hand functionality was needed to simplify loading a CLDF dataset into
a clld app.
Such functionality has now been released with clld 7.1. So, serving John Peterson’s
dataset
![]() from a
from a clld application is as simple as running a
couple of commands:
- Install
clld:pip install clld==7.1 - Create a project template suited to a CLDF StructureDataset
clld create -f peterson/ cldf_module=structuredataset --quiet - Install the (newly created) application:
cd peterson pip install -e . - Load the data into the application’s database:
clld initdb development.ini --cldf PATH/TO/cldf/petersonsouthasia/cldf/StructureDataset-metadata.json --glottolog PATH/TO/glottolog/glottolog - Start the server:
pserve development.ini
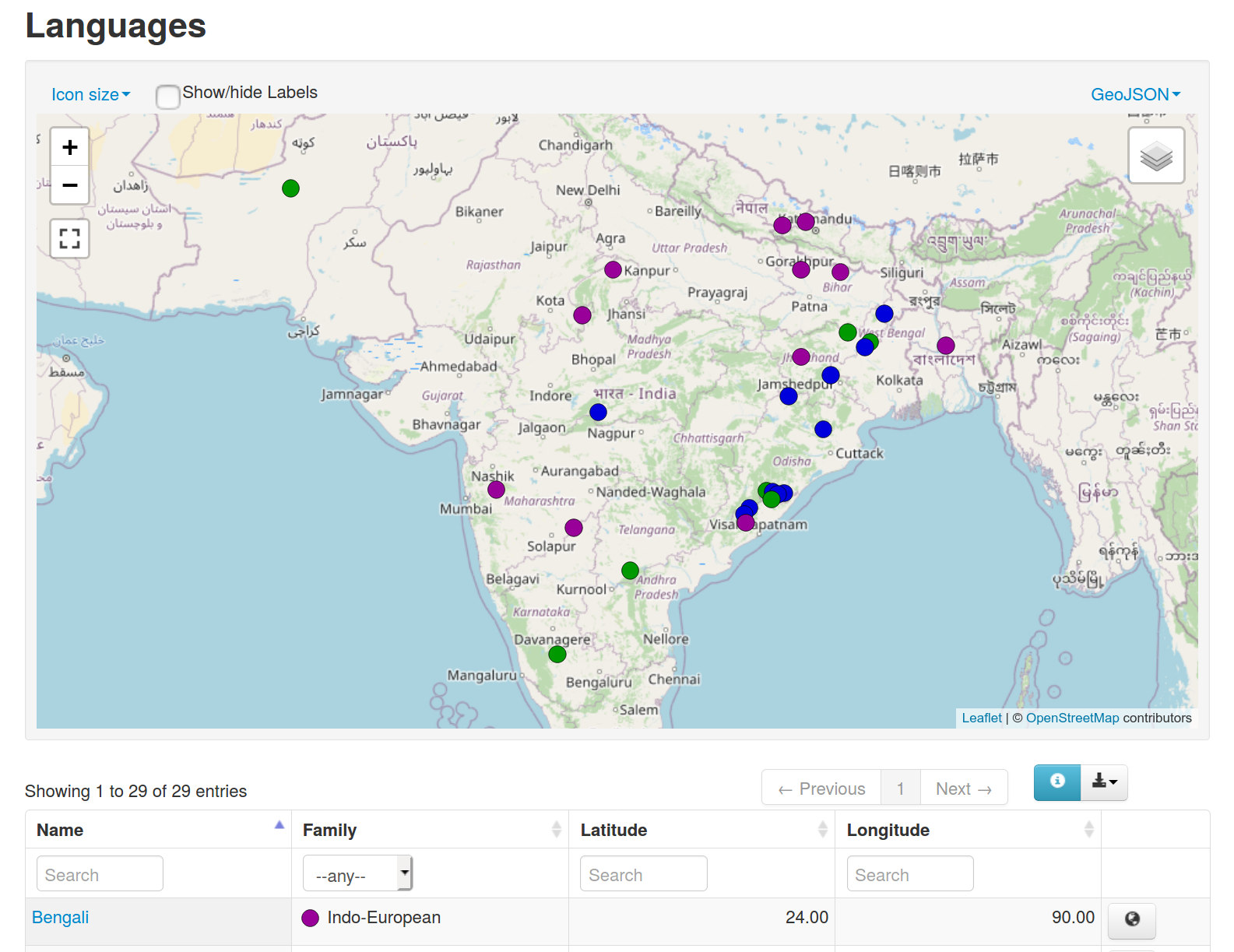
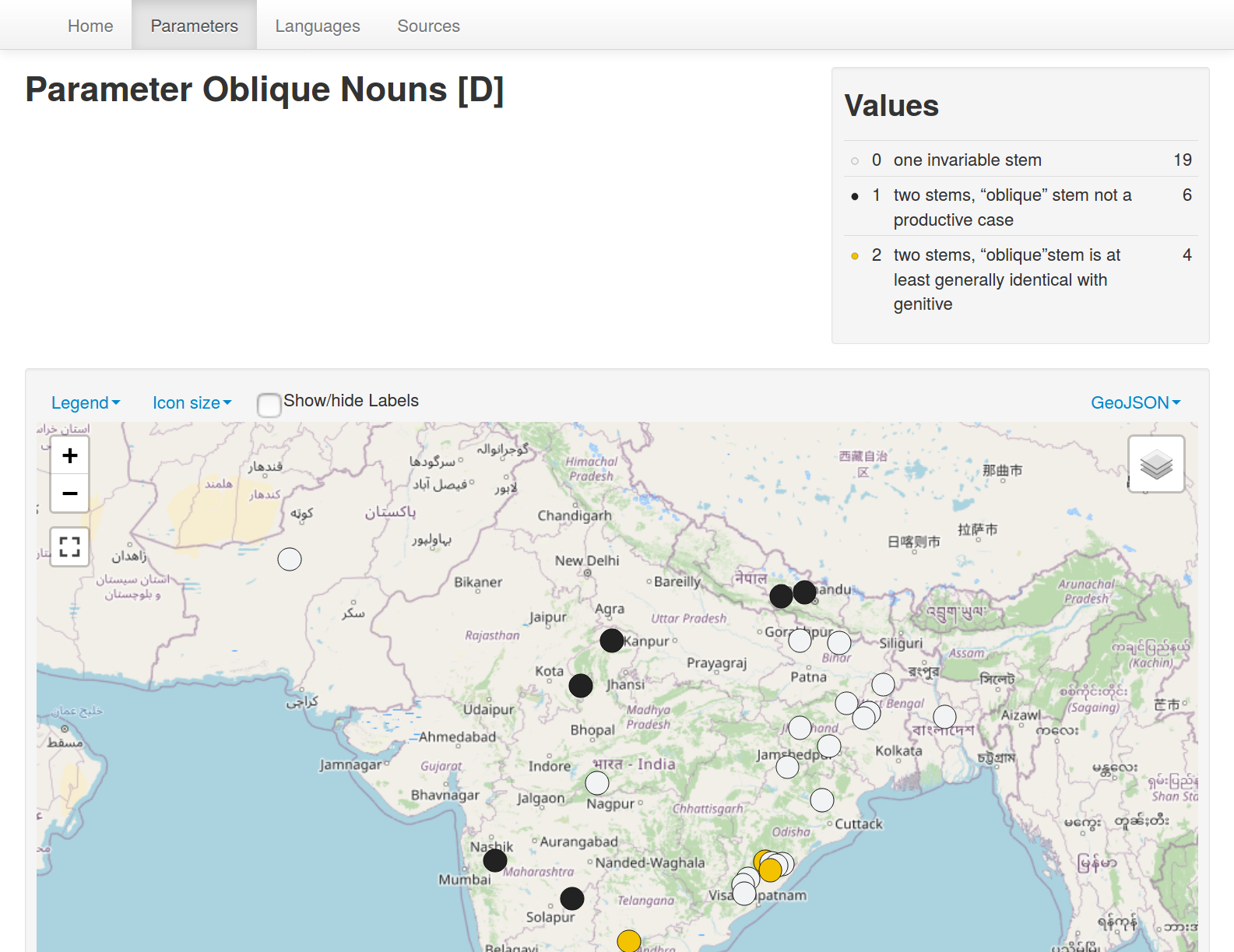
The app can then be visited locally at http://localhost:6543/ and by default supports e.g.
- languages color-coded by family:
- feature values color-coded by value:
- Previous: 14 Feb 2019 » PHOIBLE 2.0 released
- Next: 24 Sep 2020 » Retro-digitizing the "Tableaux phonétiques des patois suisses romands"

